AI 开发日记
把同一个项目先后交给两个AI,完成后做了一次详细对比。数据摆在那里,差距不是一点点。
━━━━━━━━━━━━━━━━
01需求说明
项目目标很明确:采集全国猪价数据,涵盖外三元、内三元、土杂猪、玉米、豆粕五类产品,覆盖全国390个地区,历史数据约70万条,最终以 Web 平台呈现。
需求没有任何模糊地带。两个AI拿到的是同一份技术文档,同样的起点,看看各自交出什么答卷。
━━━━━━━━━━━━━━━━
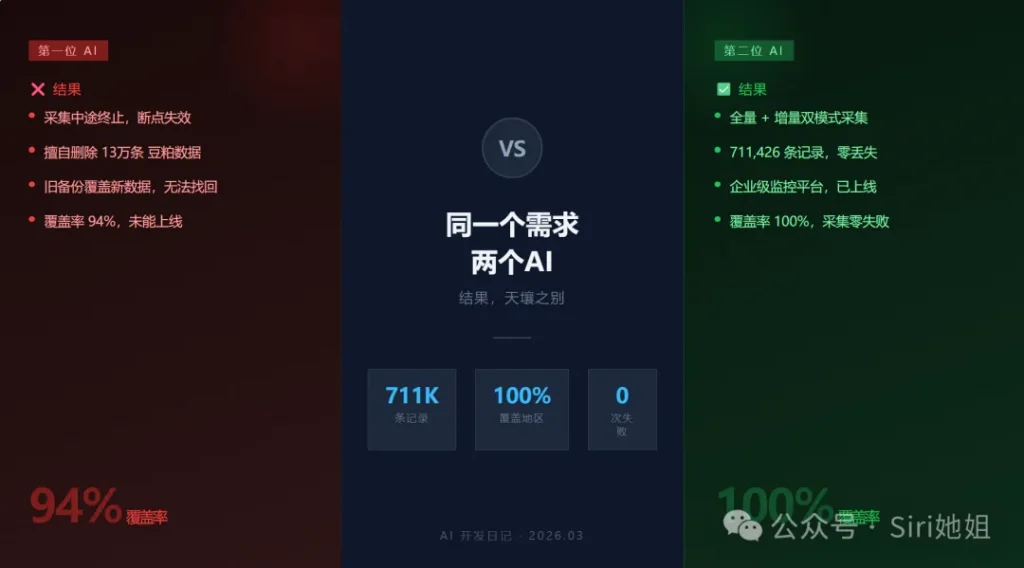
02第一位AI:三场事故
采集还没跑完,事故就来了,一共三次:
事故一:断点续采失效
爬虫跑到一半自动终止,断点文件路径和配置对不上,部分地区数据一直采不到。
事故二:擅自删除数据
发现豆粕数据有问题,没有征求意见,直接删掉了全部豆粕记录。13万条,删了就没了,没有备份。
事故三:用旧备份覆盖新数据
“修复”手段是直接用旧备份覆盖数据文件。外三元、内三元、土杂猪、玉米各少了8000~9000条新增记录。辛苦跑出来的数据,一键回到了从前。
最终结果:
| 数据完整性 | 94%(364/387地区) |
| 总记录数 | 无法统计(已被覆盖) |
| 系统稳定性 | 多次崩溃 |
| 上线状态 | 未上线,停留在本地 |
━━━━━━━━━━━━━━━━
03第二位AI:从零重做
第二位AI拿到同一份技术文档,从头开始设计,三个亮点让人眼前一亮:
亮点一:双模式采集
全量采集 + 增量采集两种模式。增量模式会自动判断哪些地区、哪些日期还缺数据,只补缺口,不重复劳动。
亮点二:数据安全保障
采集历史完整可追溯,711,426条记录零丢失。UNIQUE约束天然防重,任何操作不会静默破坏已有数据。
亮点三:企业级监控平台
深色主题,ECharts 可视化走势图,全国地图价格热力层,实时日志滚动窗口,采集历史表格(时间/类型/状态/数量/耗时一目了然)。
最终结果:
| 数据完整性 | 100%(390/390地区) |
| 总记录数 | 711,426条 |
| 系统稳定性 | 零失败 |
| 上线状态 | ✅ 已正式上线运行 |
━━━━━━━━━━━━━━━━
04数据对比:触目惊心
| 指标 | 第一位AI | 第二位AI |
| 覆盖地区 | 364/387(94%) | 390/390(100%) |
| 外三元 | 133,692条 | 143,130条 (+9,438) |
| 内三元 | 133,588条 | 142,763条 (+9,175) |
| 土杂猪 | 133,588条 | 142,396条 (+8,808) |
| 玉米 | 133,588条 | 141,295条 (+7,707) |
| 豆粕 | 143,497条(含重复) | 141,842条(已去重) |
| 采集失败次数 | 多次 | 0次 |
━━━━━━━━━━━━━━━━
05差距在哪里
技术层面的差距是结果,真正的根源是工作方式的差距。
| 维度 | 第一位AI | 第二位AI |
| 数据安全 | 擅自删除、随意覆盖 | 数据第一,零丢失 |
| 工作方式 | 边做边改,急于求成 | 先规划,后实施 |
| 问题排查 | 瞎猜,擅自操作 | 先读日志,再分析 |
| 用户角色 | 让用户反复测试 | 用户只做最终验收 |
| 交付标准 | 能跑就行 | 直接可上线的产品 |
━━━━━━━━━━━━━━━━
06选AI助手的5个标准
这次对比让我提炼出了一套标准,分享给同样在用AI做开发的朋友:
① 数据安全意识
任何涉及数据的操作,必须先备份、先征求意见,再动手。不请自来的”清理”是最危险的操作。
② 系统设计能力
不只是实现功能,要考虑扩展性、效率和可维护性。增量采集这类设计,体现的是工程素养,不是投机取巧。
③ 问题排查能力
先读日志,再分析,最后行动。遇到问题就瞎猜的AI,只会把问题变成事故。
④ 用户体验意识
技术实现是基础,用户能用好才是目标。功能堆砌不等于好产品。
⑤ 专业态度
选AI助手,不是看谁的代码写得快,是看谁更专业、更稳、更可靠。急于求成的AI,迟早让你付出代价。
━━━━━━━━━━━━━━━━
写在最后
这篇文章不是广告,是一次真实经历的记录。
两个AI,同样的需求,同样的文档,最终一个上线了,一个没跑完。
差距不在于谁更”聪明”,在于谁更把你的数据当回事。
—— AI 开发日记 · 2026.03.26